NoSQL(NoSQL = Not Only SQL ),意即”不仅仅是SQL”
MongoDB 是由数据库(database)、集合(collection)、文档对象( )三个层次组成
MongoDB (文档型数据库):提供可扩展的高性能数据存储
1、基于分布式文件存储
2、高负载情况下添加更多节点,可以保证服务器性能
3、将数据存储为一个文档
易于读写的BSON(二进制JSON)格式来存储数据
关系型数据库遵循ACID规则
事务在英文中是transaction,和现实世界中的交易很类似,它有如下四个特性:
1、A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
2、C (Consistency) 一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。
3、I (Isolation) 独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
比如现在有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
4、D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失
(疑惑:即使每次修改后缓存都执行写回操作?不只是写回,还需要保存到磁盘?)
RDBMS 对比 NoSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL) (SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
-键 - 值对存储,列存储,文档存储,图形数据库 - 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
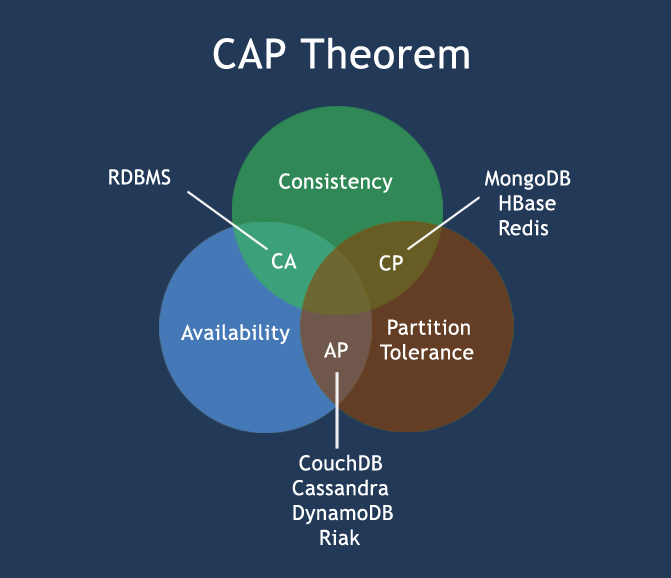
CAP定理(CAP theorem)
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer’s theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分区容错性(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
NoSQL的优点/缺点
优点:
- 高可扩展性
- 分布式计算
- 低成本
- 架构的灵活性,半结构化数据
- 没有复杂的关系
缺点:
- 没有标准化
- 有限的查询功能(到目前为止)
- 最终一致是不直观的程序
基本操作
use database # 切换/创建数据库
show dbs # 查看所有数据库
db.dropDatabase() # 删除数据库
db.version() # 查看版本
show tables # 查看所有集合
db.col.drop() # 删除集合
db.serverStatus() # 获取服务状态信息
db.col.stats() # 查看数据表的详细信息,如表大小
db.createCollection("runoob") # 创建集合
db.col.find().pretty() # 格式化打印集合
# 列不存在直接就创建了
# 数据库表如果没有,使用use newdata也会直接创建了
# 使用update同理,创建status列默认值是0
db.runoob.update({},{$set:{status:0}},false,true)
# 插入字段
db.col.insert({title:'Mongo'})
db.col.insertOne({title:'MongoDB',url:"http://www.mongo.org",tags:['mongo','db','NoSQL']})
# 插入多条
db.col.insertMany([
{title:'MongoDB',url:"http://www.mongo.org",tags:['mongo','db','NoSQL']},
{title:'MySQL',url:"http://www.mysql.org",tags:['mysql','db']},
{title:'PostgreSQL',url:"http://www.postgre.org",tags:['pgsql','db']},
])
# 更新文档名
db.col.update({}, { $rename: { 'oldFieldName': 'newFieldName' } }, { multi: true })
# 更新所有文档
db.asset_info.updateMany({}, {$set: {age: 12}})
# 更新符合条件的第一条文档
db.asset_info.updateMany({title:'Mongo'}, {$set: {age: 12}})
# 更新符合条件的所有文档
db.asset_info.updateMany({title:'Mongo'}, {$set: {age: 12}},{multi:true})
# 只更新第一条记录:
db.col.update( { "count" : { $gt : 1 } } , { $set : { "test2" : "OK"} } );
# 全部更新:
db.col.update( { "count" : { $gt : 3 } } , { $set : { "test2" : "OK"} },false,true );
# 只添加第一条:
db.col.update( { "count" : { $gt : 4 } } , { $set : { "test5" : "OK"} },true,false );
# 全部添加进去:
db.col.update( { "count" : { $gt : 5 } } , { $set : { "test5" : "OK"} },true,true );
# 全部更新:
db.col.update( { "count" : { $gt : 15 } } , { $inc : { "count" : 1} },false,true );
# 只更新第一条记录:
db.col.update( { "count" : { $gt : 10 } } , { $inc : { "count" : 1} },false,false );
# 如删除集合下全部文档
db.col.deleteMany({})
# 删除 status 等于 A 的全部文档
db.col.deleteMany({ status : "A" })
# 删除 status 等于 D 的一个文档
db.col.deleteOne({ status: "D" })
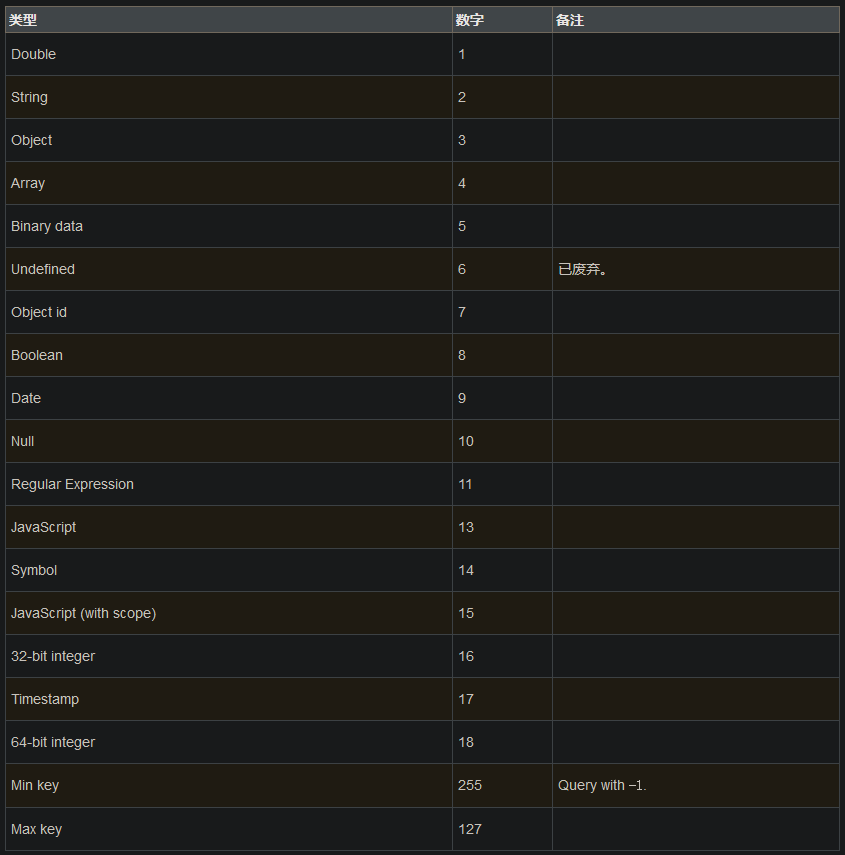
# 获取集合中title为string类型的文档
db.col.find({"title" : {$type : 2}})
db.col.find({"title" : {$type : 'string'}})
# 查询col集合中title字段的内容,跳过3条,显示2条
db.col.find({},{"title":1,_id:0}).limit(2).skip(3)
# 按照"like"字段进行降序(1是升序)
db.col.find({},{"title":1,_id:0}).sort({"likes":-1})
# 创建多个索引字段,也可以一个(关系型数据库中称作复合索引)
db.col.createIndex({"title":1,"description":-1})
# 在后台创建索引
db.values.createIndex({open: 1, close: 1}, {background: true})
# 查看集合索引
db.col.getIndexes()
# 查看集合索引大小
db.col.totalIndexSize()
# 删除集合所有索引
db.col.dropIndexes()
# 删除集合指定索引
db.col.dropIndex("索引名称")
# 设置在创建记录后,180 秒左右删除。
db.col.createIndex({"createDate": 1},{expireAfterSeconds: 180})
# 由记录中设定日期点清除。
# 设置 A 记录在 2019 年 1 月 22 日晚上 11 点左右删除,A 记录中需添加 "ClearUpDate": new Date('Jan 22, 2019 23:00:00'),且 Index中expireAfterSeconds 设值为 0。
db.col.createIndex({"ClearUpDate": 1},{expireAfterSeconds: 0})
# 其他注意事项:
# 索引关键字段必须是 Date 类型
# 非立即执行:扫描 Document 过期数据并删除是独立线程执行,默认 60s 扫描一次,删除也不一定是立即删除成功。
# 单字段索引,混合索引不支持
# 聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果
for i in db_asset_info.aggregate(
[
{'$project': {
"port_info": { # 查找结果只有port_info字段结果
'$filter': { # 字段值为筛选条件的结果
'input': "$port_info", # 筛选条件输入的列表
'as': "item", # 列表中的每个元素命名
'cond': { '$eq': [ '$$item.ProductName', 'nginx' ] } # 筛选条件
}
},
"_id": 0
},
}]
):
if i['port_info']:
print(i)
示例:
// `storage` Collection
{
"_id": "alpha",
"name": "Storage Alpha",
"items": [
{
"category": "food",
"name": "apple"
},
{
"category": "food",
"name": "banana"
},
{
"category": "tool",
"name": "hammer"
},
{
"category": "furniture",
"name": "couch"
}
]
}
查询得到:
{
"_id" : "alpha",
"items" : [
{
"category" : "food",
"name" : "apple"
},
{
"category" : "food",
"name" : "banana"
}
]
}
$type 类型对照表
索引参数
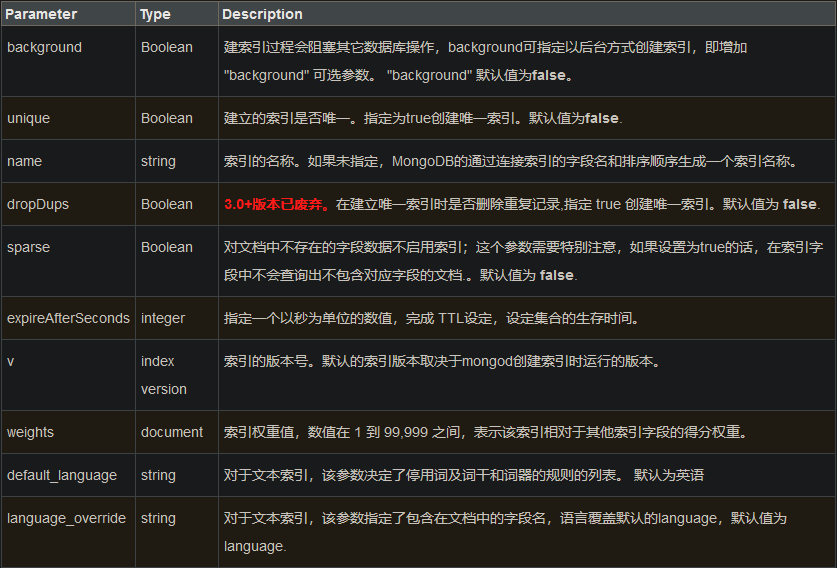
聚合表达式
管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
MongoDB复制
数据同步在多个服务器的过程,复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
复制还允许您从硬件故障和服务中断中恢复数据
- 保障数据的安全性
- 数据高可用性 (24*7)
- 灾难恢复
- 无需停机维护(如备份,重建索引,压缩)
- 分布式读取数据
复制原理:
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
副本集特征:
- N 个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
rs.initiate() # 启动一个新的副本集
rs.conf() # 查看副本集的配置
rs.status() # 查看副本集状态
rs.add(HOST_NAME:PORT) # 添加副本集的成员
db.isMaster() # 判断当前运行的Mongo服务是否为主节点
db.printReplicationInfo(); # 查看oplog状态
db.getReplicationInfo() # 可以用来查看oplog的状态、大小、存储的时间范围
db.printSlaveReplicationInfo();# 查看从库同步状态
注意:MongoDB 中你只能通过主节点将 Mongo 服务添加到副本集中
MongoDB的副本集与我们常见的主从有所不同,主从在主机宕机后所有服务将停止,而副本集在主机宕机后,副本会接管主节点成为主节点,不会出现宕机的情况
为了提高复制的效率,复制集中的所有节点之间会相互的心跳检测(ping)。每个节点都可以从其它节点上获取 oplog。可以简单的将其视作 MySQL 中的 binlog。
[mongod@db01 ~] $ mongodump --port 28017 --oplog -o /mongodb/backup #对28017实例中的数据进行全备
## --oplog参数:会记录备份过程中的数据变化,并以".bson"格式保存下来
# ...模拟故障
[mongod@db01 ~] $ mongorestore --port 28017 --oplogReplay /mongodb/backup #使用mongorestore命令恢复数据时,会自动识别/mongodb/backup目录下的 ".bson"文件
热备详细解释:
分片
在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足。
- 本地磁盘不足
- 垂直扩展价格昂贵
语法
rs.add() 命令基本语法格式如下: >rs.add(HOST_NAME:PORT)
注意:
- 集合只有在内容插入后才会创建,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建
- 在执行 remove() 函数前先执行 find() 命令来判断执行的条件是否正确,这是一个比较好的习惯
- pymongo 聚合搜索查询得到的结果是一个迭代对象,需要使用async for item in db.aggregate()得到文档
用户操作
# /etc/mongo.conf
# security:
# authorization: enabled
mongod --auth # 启动 MongoDB 时启用身份验证
mongo admin # 进入管理员管理页面
db.createUser({user:"admin", pwd:"123456", roles:[{role:"root", db:"admin"}]}) # 创建管理员用户
docker exec -ti 074 mongo -u root -p XyLNxzToVDUaKIvC --authenticationDatabase admin
mongo -u root -p [password] --authenticationDatabase admin
配置
远程连接配置
# /etc/mongo.conf
net:
port: 27017
bindIp: 0.0.0.0 # 将127.0.0.1修改为0.0.0.0
连接配置
# 打开mongo shell
mongo
mongodb://username:password@host:port/database[?options]]
报错记录
pymongo 中使用 find()查找报错’AsyncIOMotorCursor’object is not subscriptable
pymongo 中 find() 被定义为协程,需要使用异步等待,示例:
db = await db["collection"].find({"key":"value"})
就可以进行索引,db[0]
find().sort()报错,超越缓冲区大小
使用pymongo时,这行代码触发如下报错:
pymongo.errors.OperationFailure: Executor error during find command :: caused by :: Sort exceeded memory limit of 104857600 bytes, but did not opt in to external sorting. Aborting operation. Pass allowDiskUse:true to opt in., full error: {‘ok’: 0.0, ‘errmsg’: ‘Executor error during find command :: caused by :: Sort exceeded memory limit of 104857600 bytes, but did not opt in to external sorting. Aborting operation. Pass allowDiskUse:true to opt in.’, ‘code’: 292, ‘codeName’: ‘QueryExceededMemoryLimitNoDiskUseAllowed’}
我实际遇到的Mongo报错:
errMsg”:”Executor error during find command :: caused by :: Sort exceeded memory limit of 104857600 bytes, but did not opt in to external sorting. Aborting operation. Pass allowDiskUse:true to opt in.”
触发代码:
sorted_mongo_doc = mongo.find({}).sort(‘Time’, -1).limit(2000)
原因
查阅mongo中文文档(https://mongodb.net.cn/manual/reference/method/cursor.sort/#sort-limit-results),得知此报错的原因是排序内容超越32MB的内存限制。
https://mongodb.net.cn/manual/reference/method/cursor.sort/#sort-limit-results
找到如下解决方法,参考:https://segmentfault.com/a/1190000040980419
文档解释:当无法从索引获取排序顺序时,MongoDB将对内存中的结果进行排序,这要求所排序的结果集小于32 MB。
解决方法
- 设置排序字段索引
db.getCollection(‘col’).createIndex({“updatedAt”: 1})
没做尝试,略
- 提高数据库排序的内存上限
db.adminCommand({setParameter: 1, internalQueryExecMaxBlockingSortBytes: 104857600})
在pymongo中尝试失败
3.更换 aggregate (聚合搜索)进行查询
将查询语句替换如下:
sorted_mongo_doc = mongo.aggregate([
{'$project': {}},
{'$sort': {'Time': -1}},
{'$limit': 2000},
], allowDiskUse=True)
allowDiskUse=True表示使用磁盘存储
aggregate不能操作两次表
pymongo使用过程中发现,aggregate不能连续操作同一张表两次,只能执行成功一次
重复插入报错
pymongo.errors.DuplicateKeyError: E11000 duplicate key error collection: JXScan.message index: id dup key: { _id: ObjectId(‘65b9bfd52b4f663687b9f3fd’) }, full error: {‘index’: 0, ‘code’: 11000, ‘keyPattern’: {‘_id’: 1}, ‘keyValue’: {‘_id’: ObjectId(‘65b9bfd52b4f663687b9f3fd’)}, ‘errmsg’: “E11000 duplicate key error collection: JXScan.message index: id dup key: { _id: ObjectId(‘65b9bfd52b4f663687b9f3fd’) }”}
ai 解答:
这个错误信息来自于MongoDB,是在使用PyMongo库与MongoDB数据库交互时遇到的一个常见问题。DuplicateKeyError错误表明你尝试向数据库中插入一个具有唯一索引(在这个例子中是_id字段)的重复键值。
错误信息解释如下:
- E11000 是MongoDB的错误代码,表示发生了重复键错误。
- duplicate key error collection: JXScan.message index: id 指出在名为JXScan.message的集合中,_id字段(MongoDB的默认唯一索引)出现了重复的键值。
- dup key: { _id: ObjectId(‘65b9bfd52b4f663687b9f3fd’) } 显示了重复的_id值。
- keyPattern: {‘_id’: 1} 表示_id字段被设置为唯一索引。
- keyValue: {‘_id’: ObjectId(‘65b9bfd52b4f663687b9f3fd’)} 是尝试插入的重复的_id值。
- errmsg 提供了更详细的错误信息。
在MongoDB中,_id字段是自动创建的唯一索引,这意味着每个文档的_id必须是唯一的。如果你尝试插入一个已经存在的_id,MongoDB会拒绝这个操作并抛出这个错误。
我的发现:
我发现查找这个 _id 并没有发现文档,就很奇怪,删除同样找不到也没删除
解决办法:
1、 使用 save 覆盖但是就数据会丢失
2、使用 try 跳过,使用这个办法解决
try:
...
except:
pass
docker 启动mongo失败:数据未关闭
在docker中运行mongo失败,查看日志提示,锁没有释放,数据损坏或者升级的版本不兼容,我直接将容器迁移过来的,镜像是没有问题的,数据在打包的时候没有关闭镜像,可能是没有关闭 mongo 的连接导致数据文件损坏
checkpoint 检查点
mongo 执行命令耗时检查
MongoDB 几种查询嵌套数据(Embedded)的方式
MongoDB 推荐使用「内嵌文档(Embedded)」,所以带来一个问题,如何查询嵌入文档内的数据?
假如我们有一个 storage 的 Collection,包含一条数据:
// `storage` Collection
{
"_id": "alpha",
"name": "Storage Alpha",
"items": [
{
"category": "food",
"name": "apple"
},
{
"category": "food",
"name": "banana"
},
{
"category": "tool",
"name": "hammer"
},
{
"category": "furniture",
"name": "couch"
}
]
}
如何查出 items.category 为 food 的数据?
熟悉 MongoDB 查询语句的同学可能立刻想到了以下查询语句:
db.storage.find({
'items.category': {
$eq: 'food'
}
})
但是这样只能查出这一条 storage 数据,并不能过滤 items 字段中不符合条件数据,实时上就是返回了整个 document。
解决方案
$ 映射操作符(Projection Operator)
第一个解决方案是使用 $ 映射操作符。
这是 官方文档 的介绍:
$ 操作符会限制 array 类型数据的返回结果,使其仅返回第一个满足条件的元素。
那么我们使用 $ 进行查询:
db.storage.find(
{
'items.category': {
$eq: 'food'
}
},
{
'items.$': 1
}
)
就会得到这样的结果:
{
"_id" : "alpha",
"items" : [
{
"category" : "food",
"name" : "apple"
}
]
}
可以看到,不符合条件的 items 确实没有返回了(_id 字段是默认会返回的),但因为 $ 映射操作符只会返回数组中第一个符合条件的元素,另一条同样符合条件的元素无法被获取到。
$ 映射操作符还有一些其他限制条件。
$elemMatch 映射操作符(Projection Operator)
另一种方式是使用 $elemMatch 操作符(官方文档)。
同样是「映射操作符」,$elemMatch 和 $ 的区别在于,$ 使用的是数据查询条件作为来映射(或者说过滤)array 中的数据,而 $elemMatch 需要指定单独的条件(可以指定多个条件)。
查询示例如下:
db.storage.find(
// 对 `items` 的过滤条件不需要写在查询条件中
{
'_id': "alpha"
},
{
'items': {
'$elemMatch': {
'category': 'food'
}
}
}
)
查询结果:
{
"_id" : "alpha",
"items" : [
{
"category" : "food",
"name" : "apple"
}
]
}
但和 $ 一样,$elemMatch 也只能返回数组中的第一条元素。
聚合(Aggregation)
MongoDB >= 3.2
$filter
「聚合」这里我们就简单理解为对数据的批处理(分组、转换、统计等)。它的功能实际上太强大了,详细介绍还是推荐看官方文档,用它来做数组过滤其实有一些杀鸡用牛刀的感觉。
查询语句看起来有一些复杂:
db.storage.aggregate(
{
$project: {
"items": {
$filter: {
input: "$items",
as: "item",
cond: {
$eq: [ '$$item.category', 'food' ]
}
}
}
}
}
)
查询结果:
{
"_id" : "alpha",
"items" : [
{
"category" : "food",
"name" : "apple"
},
{
"category" : "food",
"name" : "banana"
}
]
}
终于我们得到了想要的结果!
$unwind
同样使用「聚合」,还可以使用 $unwind 操作符。
如果文档中包含 array 类型字段、并且其中包含多个元素,使用 $unwind 操作符会根据元素数量输出多个文档,每个文档的 array 字段中仅包含 array 中的单个元素。
我们来试试看:
db.storage.aggregate(
{
$match : {
'items.category': 'food'
}
},
{
$unwind : '$items'
},
{
$match : {
'items.category': 'food'
}
}
)
查询结果:
{
"_id" : "alpha",
"name" : "Storage Alpha",
"items" : {
"category" : "food",
"name" : "apple"
}
}
{
"_id" : "alpha",
"name" : "Storage Alpha",
"items" : {
"category" : "food",
"name" : "banana"
}
}
$unwind 操作符返回了多条文档数据,并且改变了 items 字段的类型。
不过查询语句相对前一个例子来说要简洁和易于理解,在某些场景下可能更好用。
应用层过滤处理
如题,如果数组内容不多,取出整个文档后在应用层进行处理也不失为一个方法,可以说是分布式计算了……
总结
总结一下目前的结论(当前 MongoDB 版本为 3.6):
- 如果只需要获取 array 字段中的第一个满足条件的元素、并且一次查询中仅操作一个 array 类型的字段,使用 $ 或者 $elemMatch 映射操作符都可以满足需求;
- 其他情况,优先考虑使用「聚合」;
- 没有强迫症也可以在应用层做过滤处理。
这个结论让我也颇感意外,因为「内嵌式」建模方式是 MongoDB 官方宣传的亮点之一(官方文档,当年的宣传文档我暂时没找到)。如果你有更好的方案请在评论中指出。
参考
- How to get a specific embedded document inside a MongoDB collection?
- Retrieve only the queried element in an object array in MongoDB collection
查看mongodb执行命令耗时
1.开启日志,超过10毫秒的都记录
db.setProfilingLevel( 1 , 10)
2.执行命令
db.metric.aggregate([{$group: {_id: '$month', totalcnt: {$sum: 1}}}])
3.查看执行情况
> db.system.profile.find().pretty()
{
"op" : "command",
"ns" : "db_test.metric",
"command" : {
"aggregate" : "metric",
"pipeline" : [
{
"$group" : {
"_id" : "$month",
"totalcnt" : {
"$sum" : 1
}
}
}
],
"cursor" : {
},
"lsid" : {
"id" : UUID("fda589d9-c981-4f93-9341-fca9980f77b3")
},
"$readPreference" : {
"mode" : "secondaryPreferred"
},
"$db" : "db_test"
},
"keysExamined" : 0,
"docsExamined" : 1000000,
"cursorExhausted" : true,
"numYield" : 1026,
"nreturned" : 1,
"locks" : {
"ReplicationStateTransition" : {
"acquireCount" : {
"w" : NumberLong(1058)
}
},
"Global" : {
"acquireCount" : {
"r" : NumberLong(1058)
}
},
"Database" : {
"acquireCount" : {
"r" : NumberLong(1057)
}
},
"Collection" : {
"acquireCount" : {
"r" : NumberLong(1057)
}
},
"Mutex" : {
"acquireCount" : {
"r" : NumberLong(31)
}
}
},
"flowControl" : {
},
"storage" : {
},
"responseLength" : 149,
"protocol" : "op_msg",
"millis" : 1732,
"planSummary" : "COLLSCAN",
"ts" : ISODate("2022-03-24T03:29:11.433Z"),
"client" : "192.168.1.135",
"appName" : "MongoDB Shell",
"allUsers" : [ ],
"user" : ""
}
这里执行1732毫秒
4.关闭日志
db.setProfilingLevel(0)
对于总数的查询速度
大量数据下,计算文档数量
- 使用 mongo shell 命令 db[‘TF’].count(),它会立即返回(300w 条耗时 0.201s)
- 使用 pymongo db[‘TF’].count_documents({}),需要很长时间(300w 条耗时 3.2s)
- 使用 pymongo 中的 db_thread.estimated_document_count(),很快返回(300w 条耗时 0.0288s)
count 是原生的 Mongo 函数。它并没有真正计算所有文件。每当 Mongo 中插入或删除一条记录时,它都会缓存集合中的记录总数。运行 count 时,Mongo 将返回该缓存值
count_documents 使用查询对象,这意味着它必须遍历所有记录才能获得总计数。因为没有传递任何参数,所以它必须遍历所有 300w 条记录。这就是它速度慢的原因
对于 PyMongo 3.7+ 版本,可以使用 estimated_document_count 方法来获取一个基于集合元数据的快速计数估计。这个方法通常比 count_documents 要快,因为它不需要遍历整个集合。但是,它可能不会总是返回精确的文档数量,而是一个估计值
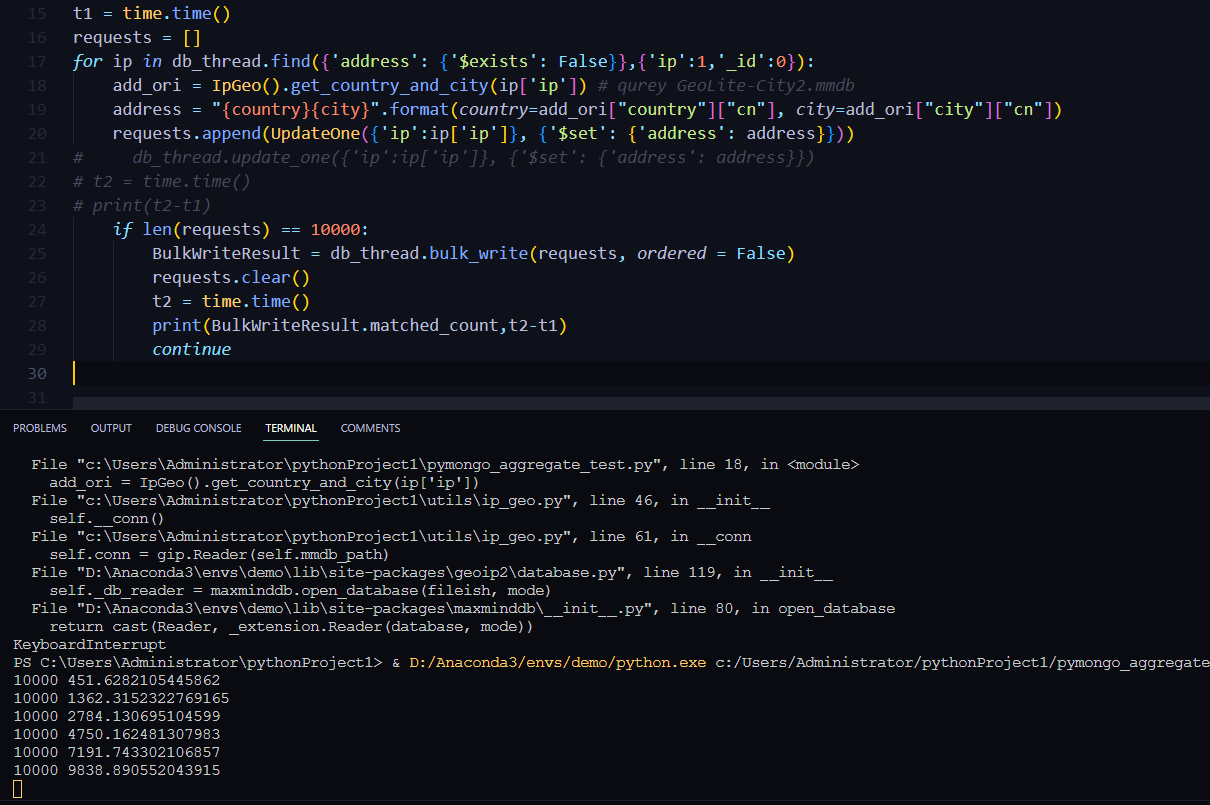
Pymongo 批量插入
bulk_write(requests:Sequence[ _WriteOp[ _DocumentType ] ], ordered : bool=True, bypass_document_validation : bool=False, session:ClientSession|None=None, comment:Any|None=None, let:Mapping|None=None)→BulkWriteResult
Requests are passed as a list of write operation instances ( InsertOne, UpdateOne, UpdateMany, ReplaceOne, DeleteOne, or DeleteMany). ;
Parameters:
- requests: A list of write operations (see examples above).
- ordered (optional): If True (the default) requests will be performed on the server serially, in the order provided. If an error occurs all remaining operations are aborted. If False requests will be performed on the server in arbitrary order, possibly in parallel, and all operations will be attempted.
- bypass_document_validation: (optional) If True, allows the write to opt-out of document level validation. Default is False.
- session (optional): a ClientSession.
- comment (optional): A user-provided comment to attach to this command.
- let (optional): Map of parameter names and values. Values must be constant or closed expressions that do not reference document fields. Parameters can then be accessed as variables in an aggregate expression context (e.g. “$$var”).
# 示例
from pymongo import MongoClient, UpdateOne, InsertOne
requests = [InsertOne({'b': 1}), UpdateOne({'a': 1}, {'$set': {'c': 1}}))]
result = db.test.bulk_write(requests, ordered=True)
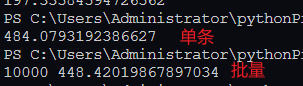
场景:使用循环中每次查询到就更新和批量更新的对比
5000 条数据对比:
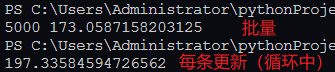
10000 条数据对比: